Recently someone brought the concept of Remembrance Agents to my attention. Remembrance Agents are programs which augment the human memory by displaying documents, such as notes and emails, that are potentially relevant to the current context. This fascinated me, and I thought I could potentially incorporate something similar into my braindump workflow, so I set aside some hours to see how I could get a proof-of-concept out.
Existing Software
A simple Github search reveals that any relevant software is dated and unmaintained. NLP has come really far in the past decade, and new techniques should definitely contribute to higher quality recommendations.
Several other techniques seemed plausible off the top of my mind. Topic models such as Latent Dirichlet Allocation (on which I spent a year researching on) could compute topics and their topical similarities. It even has an online learning algorithm, which makes it an attractive solution with an ever-growing knowledge dump. I wasn’t sure how to handle documents that are constantly changing (edited), so I just left that as a thought.
Recoll is a mature indexing and search tool that does a fantastic job of retrieval, but is based on keyword search. It would not be able to detect documents that are similar, despite using different words. However, it had a feature which indexes every web-page I visit, and it was interesting enough for me to try out, so I went with Recoll.
Setting Up Recoll
After installing Recoll, I installed the firefox extension, which queues every page I visit for processing. I then setup Recoll to run as a daemon on startup, with the following config:
topdirs = ~/.org/braindump/org/ ~/Downloads
monitordirs = ~/.org/braindump/org/ ~/Downloads
processwebqueue = true
Writing Org-Remembrance
Similar to the original Remembrance Agents design, I wanted
org-remembrance to be unintrusive. Hence I’ve decided that it would:
- Run only when idle for some time. Here I chose 2 seconds.
- Choose automatically what to query. I arbitrarily decided to use a window of words around the current word-at-point as the query.
I went though org-recoll’s code and Recoll’s documentation to see what I could adapt. Org-recoll did not provide some results that I wanted, such as the relevancy rating, so I rewrote some of the parsing logic.
After about 3 hours, I had something decent working, and the code can be found here.
Demo
Here it is updating the queries after I’m idle for 2 seconds, using the words around it.

Figure 1: Automatically updating the query after 2 seconds of idle time
One can also query a region manually, by marking a region:
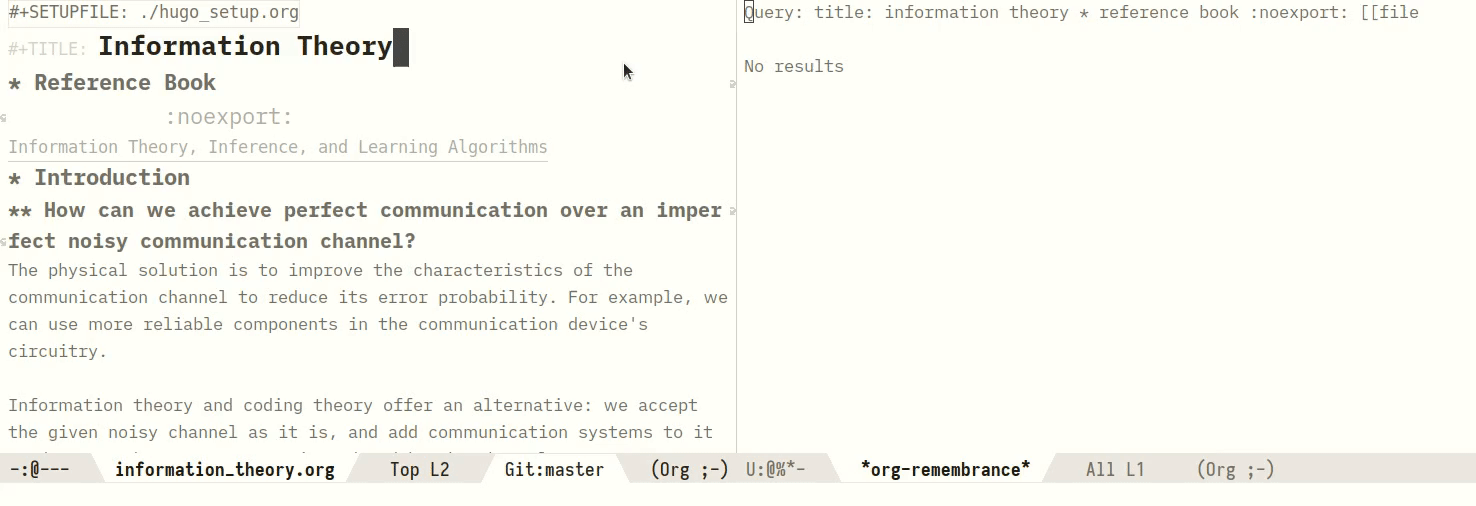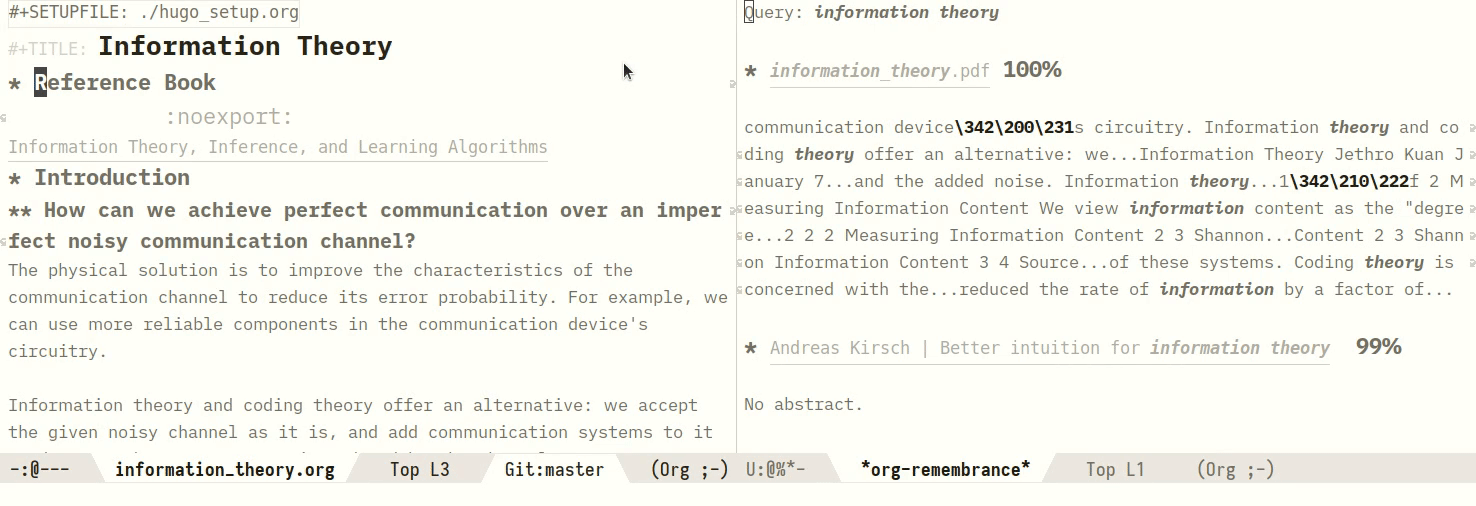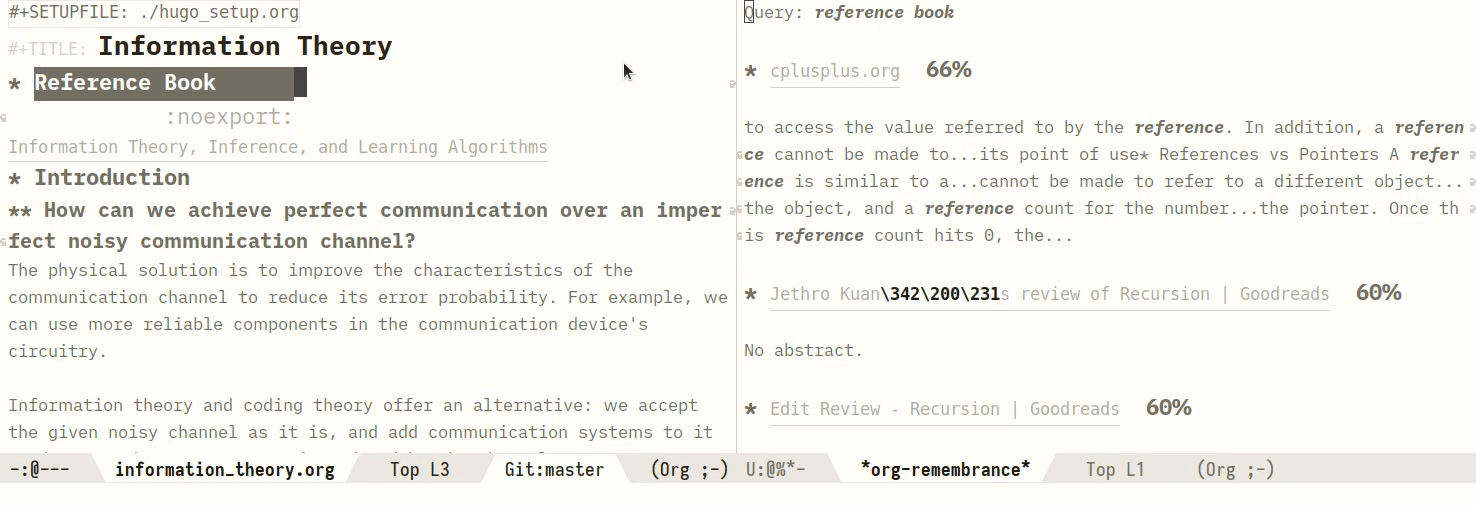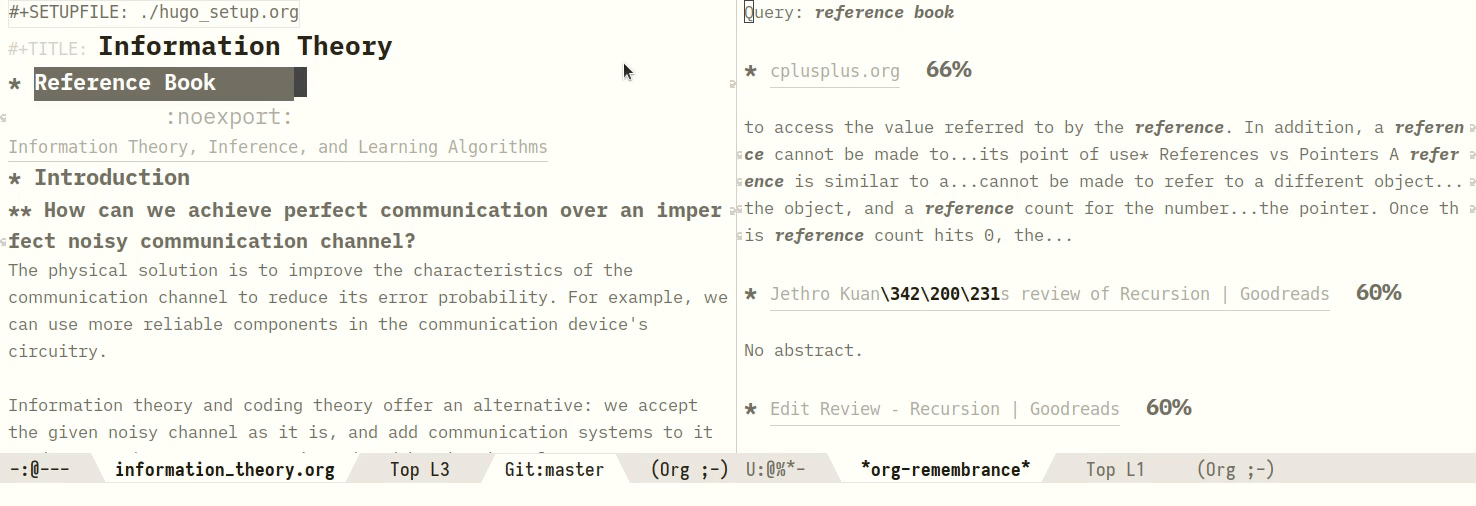
Figure 2: Manually querying using a region
Was it useful?
I tried this out for a while, and have concluded that the results that I got back weren’t useful enough to warrant my attention, for several reasons:
- The queries contain stop-words, which reduces the relevancy of the search
- It’s difficult to guess the user’s intent
- I was not indexing enough documents (only my notes), so there was little relevant information to resurface anyway
Manual searches produced better results, and sometimes surfaced relevant web pages that I’ve visited, but that is not the selling point of Remembrance Agents.
Extensions
Perhaps this would be more useful if I could augment local results with search results found on the web, similar to how Google’s search engine guesses a user intent, showing cards like:
- Word definitions
- Answers on Stack Overflow
- Summaries on Wikipedia
I’d think using topic models would take this a notch further. Using entire paragraphs as the query should give more robust results.
Let me know if you find good software that implements the ideas of Remembrance Agents well! This has certainly been an interesting exercise, and I’d say for just 3 hours of hacking, well worth-it.
(Discussion on Reddit)